
Various novel computing architectures, like massively parallel and multi-core, as well as computing accelerators, like GPUs or TPUs, continue to emerge regularly. In order to harvest the performance benefits of these architectures to the full extent and speed up the simulation, the source code has to be inevitably rewritten, sometimes almost completely. The biggest challenge here in terms of complexity, variety and size is linearization procedure since it depends on the governing equations, choice of primary unknowns, physical/chemical phenomena taken into account, and other factors. Here we present a version of DARTS fully offloaded to GPU device with efficient linear and nonlinear solvers.
Previously implemented linearization procedure at GPU device3 was recently complimented with advanced linear solver. At the moment, DARTS is capable of performing the solution of the linear systems arising from any existing physical engine entirely on GPU. Using publicly available cuBLAS, cuSPARSE and AMGX libraries, complemented by our own developed two-stage CPR reduction preconditioner, the linear solver is capable to run 10x-15x faster than on a CPU for large enough models. Fig.2 shows the performance of simulation on full SPE10 model with the original dead-oil physics (~2.2M unknowns) and compositional physics representing supercritical CO2 injection for Enchanced Oil Recovery (~4.4M unknowns).
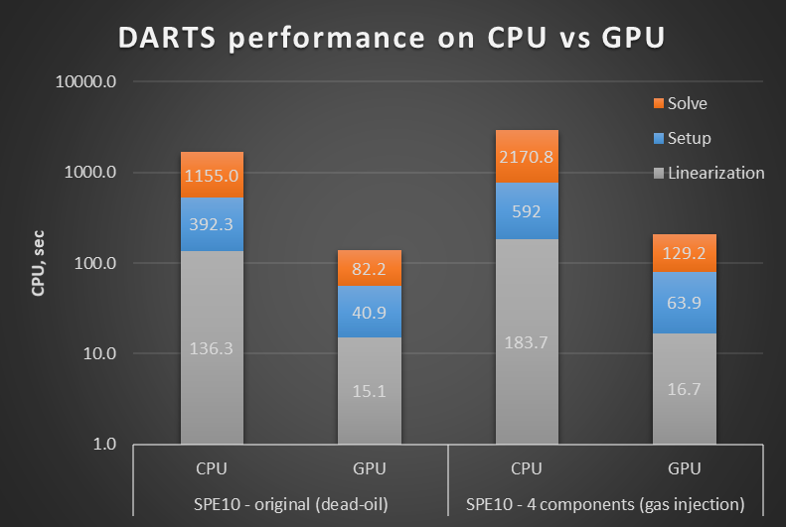
These results were obtained on Intel(R) Core(TM) i7-8086K (4.2 GHz) processor with NVidia GeForce RTX 2080 Ti card. Notice that this performance is achieved with a gaming-class GPU card (~€1000 worth) which is pluggable to a regular desktop. Using such a card, the total time required for the solution of the full SPE10 comparative problem becomes less than 3 minutes. With this extension, DARTS provides the flexible, modular, computationally efficient